
Tonal Preservation in Speech AI: A Yoruba Case Study
In Yoruba, the tone you place over a vowel is the difference between father and priest. Bàbá, low then high, is your father. Babá, mid then high, is a priest. The two words look identical the moment you strip the tone mark, which is what most speech AI does when it transcribes Yoruba.
What follows is a short note on a small benchmark we built to put a number on that gap. The metric is called Tonal Preservation Rate, the test set is eighteen sentences sourced from FLEURS, and the result is the kind of finding model cards never quite say out loud.
The thing that breaks
Yoruba is a very tonal language. Compared to English, tone is not stylistic but essential in carrying meaning. The same syllables with different tones produce different words, and the gap between two words separated only by a tone mark is often the gap between two unrelated meanings. Bàbá is father, babá is priest, bábá (with both syllables high) is the verb "it happened." A Yoruba reader scanning a sentence without tone marks can sometimes recover the intended sense from context. A downstream system, trained to act on text it receives, cannot.
The pattern repeats across the language. Ọkọ̀ is vehicle. Ọkọ, with the low mark dropped, is husband. Sùn means sleep. Sun, with no mark, means burn. Wá means come. Wà means exist. Three of those last four are distinguished only by the tone mark on a single vowel.
The convention in automatic speech recognition is to evaluate against Word Error Rate, which normalizes diacritics during scoring. Strip bàbá, babá, and bábá of their accents and all three become baba. All three match. A model can fail at the layer that determines meaning and the benchmark numbers will not flag it.
What we did
We took eighteen Yoruba sentences from the FLEURS dataset, each chosen because it contained a tonal minimal pair, and ran the audio through three systems.
Whisper-large-v3, OpenAI's open multilingual model, lists Yoruba among its supported languages. SeamlessM4T v2 is Meta's flagship multimodal speech foundation model, and Yoruba is among the languages it officially covers. The third system is what we call Nasari Yoruba speech recognition. We adopted HypaAI's Yoruba-specialized model as our base and run it in production as part of our voice agent.
We defined Tonal Preservation Rate as the percentage of utterances where the system's transcription preserves all tone bearing distinctions necessary to recover the intended meaning. Scored against tone marked ground truth, the numbers came out like this.
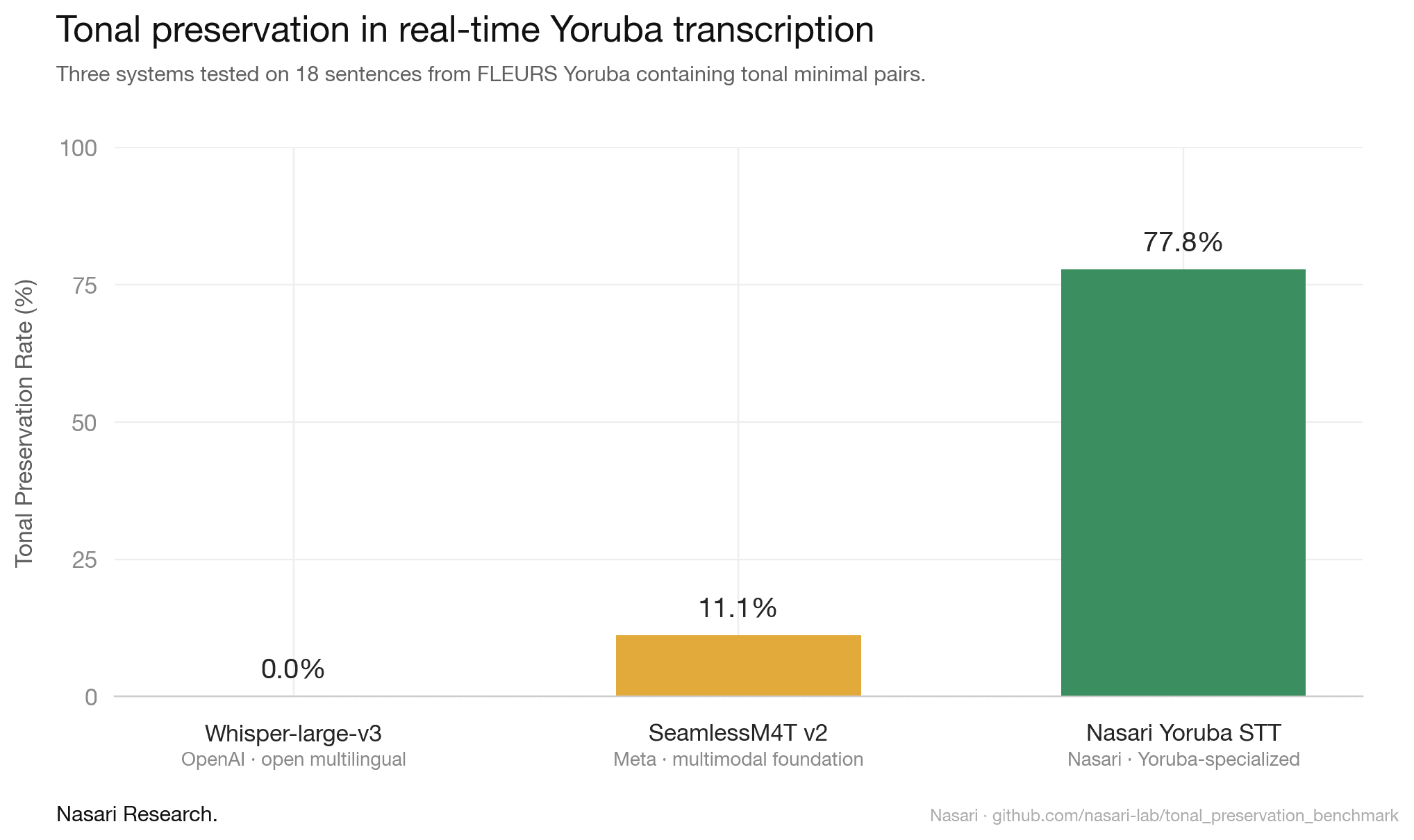
For completeness, we also tested Microsoft Azure Speech-to-Text. Yoruba is not in its supported language catalog. Neither are Igbo, Hausa, or Twi, which together represent over one hundred and seventy million speakers across West Africa.
Two layers of failure
Sitting with the numbers makes one thing clear. There are two layers of failure here, not one, and they show up in different systems for different reasons.
The first layer is recognition. Whisper-large-v3 does not produce tone stripped Yoruba. It produces something that barely resembles Yoruba at all, transcriptions that read like phonetic approximations from a listener who has never heard the language. The model fails to recognize Yoruba phonology in any meaningful sense, which is what it looks like when a language is in the model card without the training data to back it up.
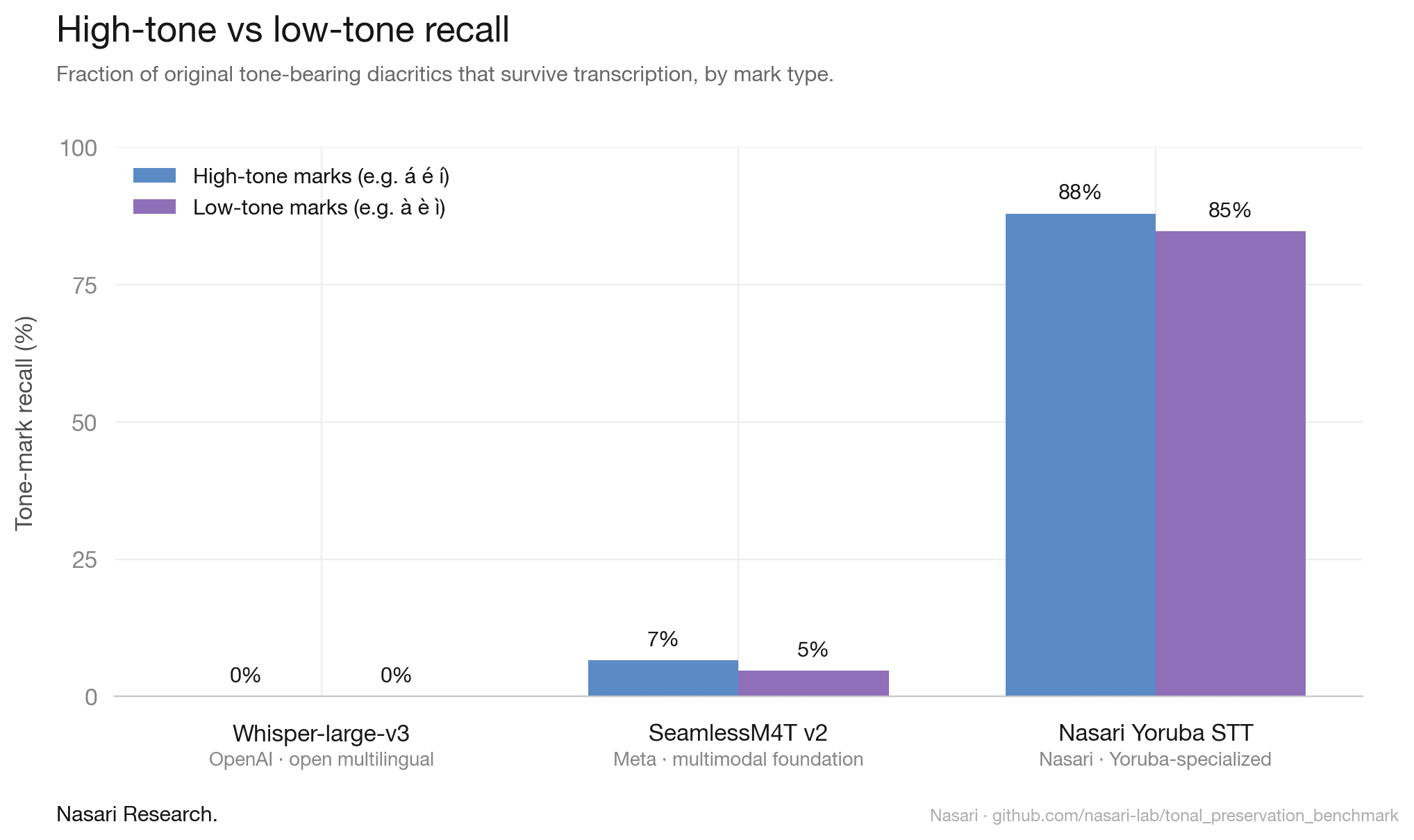
The second layer is tonal preservation. SeamlessM4T transcribes Yoruba. It gets the phonemes mostly right. It just drops the tones, every time. The output reads, to any Yoruba reader, as a sentence that has had its meaning surgically removed while leaving the shape intact. This is the more interesting failure. The model knows the language exists. It has not learned the system by which the language carries meaning.
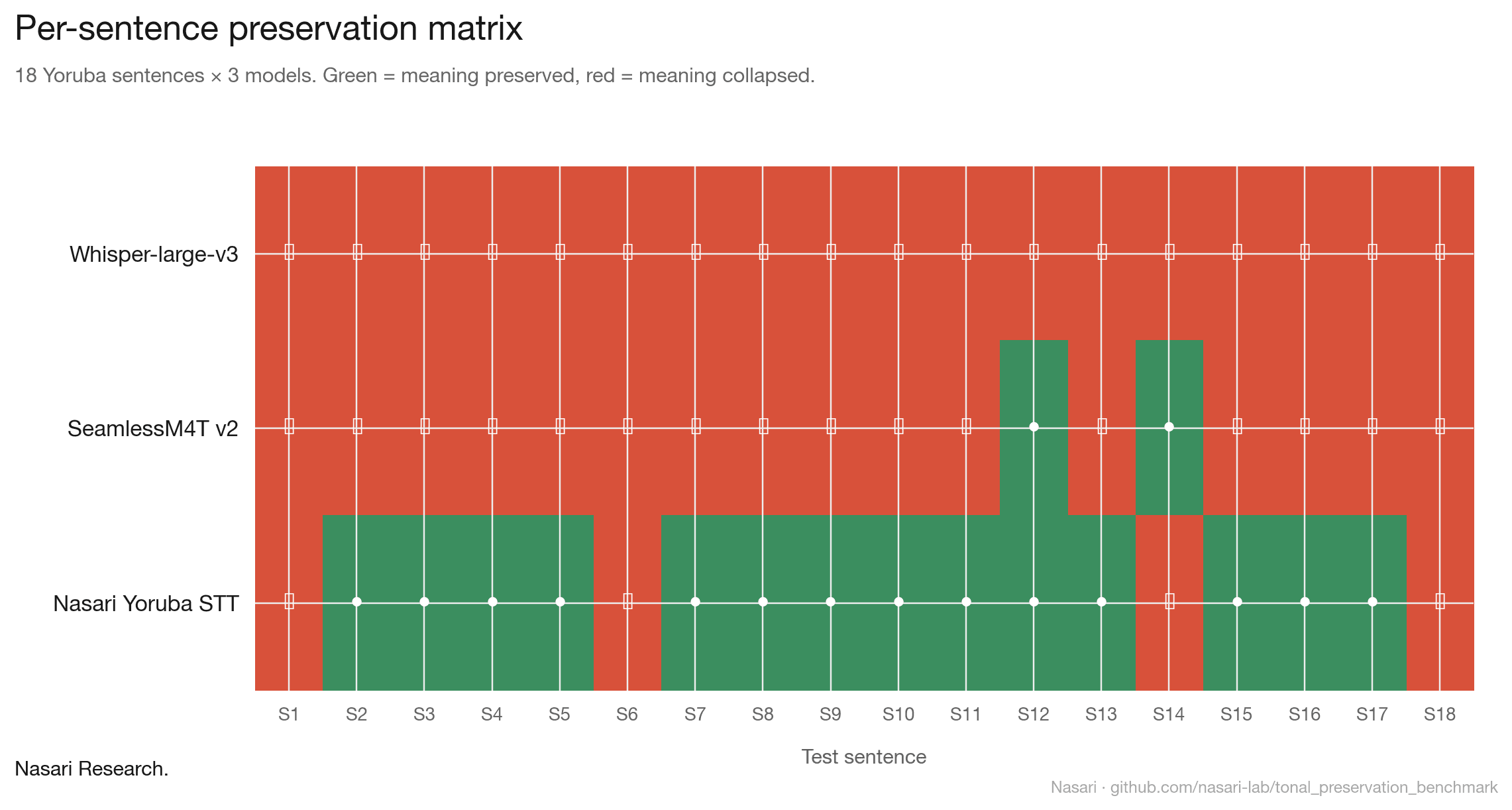
The Yoruba specialized model does both layers. It transcribes, and it preserves tones. Four of the eighteen sentences still failed, but on those the failure was partial strip rather than total. Tonal preservation under real time conditions remains hard, and we are not claiming a solved problem. The point is that the gap is fixable, and that "supports a language" is a claim worth verifying.
Why this matters now
The next wave of voice AI is real time and multimodal. GPT-4o Realtime, Gemini Live, the Thinking Machines Interaction Models. These systems are being released to the global market with broader language coverage than their predecessors, and the standard benchmarks they are evaluated against still do not measure the layer that breaks meaning in tonal languages.
For the two billion people who speak tonal languages, a model can score well on every public benchmark and still produce systematically broken output in production. A voice agent that hears ọkọ̀ (vehicle) and writes ọkọ (husband) will route the conversation accordingly. Insurance claims, medical referrals, emergency triage, financial transactions. The failure is upstream of every product that depends on accurate transcription, and most of the products built on top of today's flagship models will inherit it without realising.
Tonal Preservation Rate is not the final word on this. It is a first cut. The point is that the gap exists, that it can be measured, and that the measurement should be public.
What this version does not do
The test set is small. Eighteen sentences from a single news style corpus is enough to illustrate the gap. It is not enough to claim full coverage, and the next version targets one hundred sentences across multiple registers including conversational and broadcast.
The scoring is binary per sentence. A more nuanced metric would weight per vowel correctness and offer partial credit, and we are working on that. We tested transcription only. Real time interaction is bidirectional, and a text-to-speech system that mispronounces tones in synthesized speech is a symmetric failure deserving its own measurement. That work is for the next benchmark version.
We have not yet tested the live multimodal systems against this metric. Adding them is the next priority, and once we have access, the results will be added to the same public table.
The artifact
The benchmark, code, test set, and per sentence results are public. If you work on speech AI and want to contribute test sentences in your language of expertise, the repository is open. If you work on a system we have not yet tested and want to add your numbers to the comparison, the methodology is documented end to end.